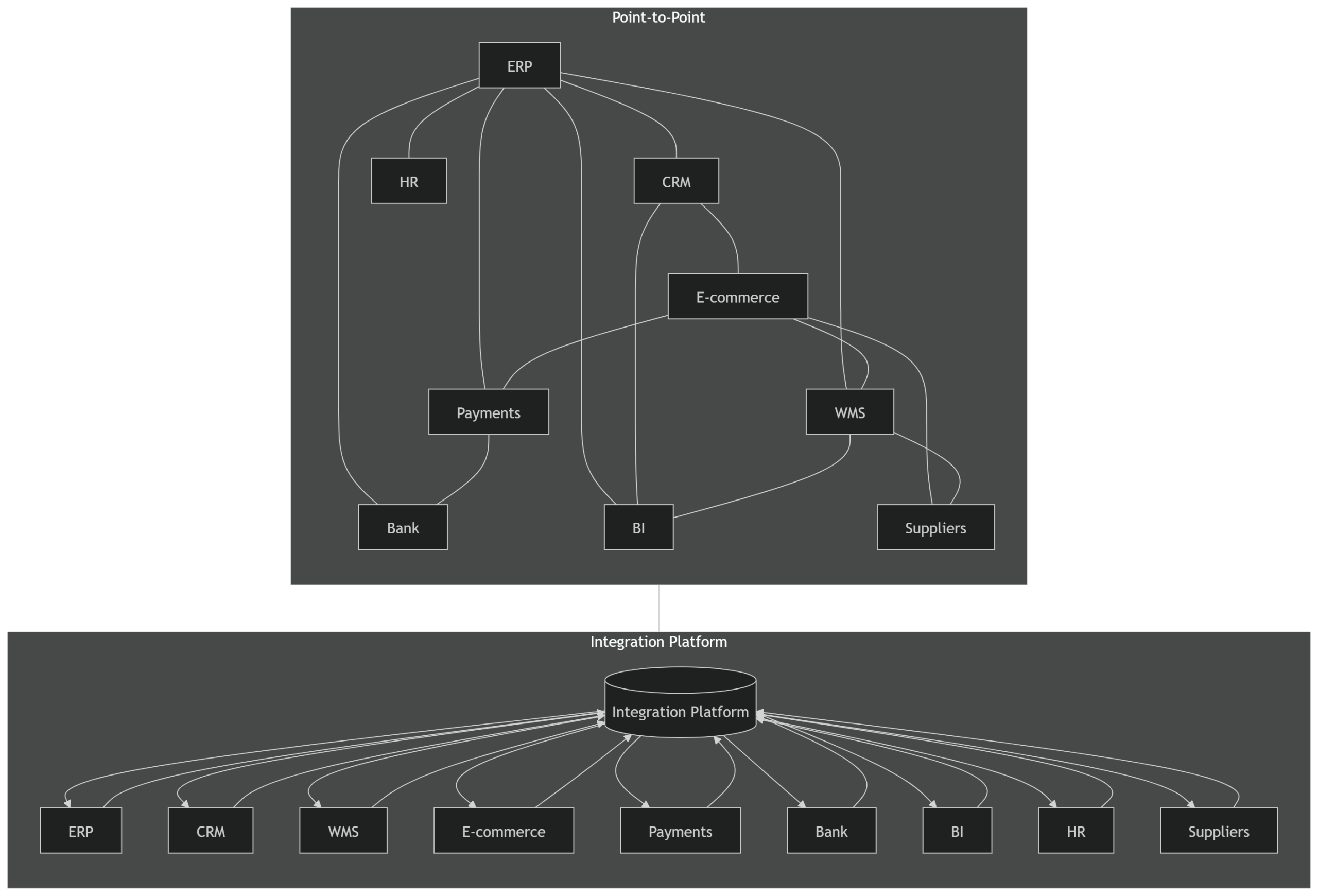
An integration platform and a cloud ETL platform are not the same thing.
They both move data.
That is why they are often confused.
But they solve different problems.
The integration platform runs the business.
The ETL and AI platform studies the business.
The business example
Return to the seafood processing company.
It needs operational integrations:
- Orders from ERP to warehouse
- Batch data from production to quality control
- Stock updates from warehouse to ERP
- Shipment booking to transport partners
- Invoice basis from ERP to finance
These flows affect daily operations. If they stop, the business is disrupted.
The same company also needs analytical data:
- Production yield trends
- Stock forecasting
- Customer demand analysis
- Transport cost analysis
- Quality deviation patterns
- AI models that predict demand, waste or capacity problems
These flows help the business understand itself and plan better.
Both are important.
But they should not be the same platform.
Two different responsibilities
%%{init: {'theme': 'dark'}}%%
graph TD
OPS[Operational Systems] --> INT[Integration Platform]
INT --> OPS2[Operational Systems]
OPS --> ETL[Cloud ETL Platform]
ETL --> LAKE[Data Lake / Warehouse]
LAKE --> AI[AI / Analytics]The integration platform handles operational movement.
- Fast enough for business processes
- Reliable enough for production
- Traceable enough for support
- Controlled enough for change
- Clear enough for ownership
The ETL and AI platform handles analytical consumption.
- Historical storage
- Aggregation
- Data modelling
- Reporting
- Forecasting
- Machine learning and AI workloads
One is about running the business.
The other is about learning from the business.
Why separation matters
If the ETL platform becomes the integration platform, analytical concerns start leaking into operational flows.
That creates problems.
- Batch timing starts affecting business processes
- Reporting transformations become operational dependencies
- AI pipelines consume data before operational meaning is clear
- Failure handling is optimized for data loads, not business recovery
- Ownership becomes unclear between operations, analytics and development
This is dangerous because ETL pipelines often tolerate things operational systems cannot tolerate.
- Late data
- Duplicate data
- Partial loads
- Reprocessing
- Schema drift
- Eventually correct results
Those may be acceptable in analytics.
They are not always acceptable when booking transport, reserving stock, approving quality documentation or sending invoice basis.
Operational integration needs correctness at the point of business action.
Analytics can often correct itself later.
The wrong architecture
A common mistake is to route everything through the cloud data platform because it already has connectors, storage and transformation tools.
%%{init: {'theme': 'dark'}}%%
graph LR
ERP[ERP] --> ETL[Cloud ETL Platform]
WH[Warehouse] --> ETL
PROD[Production] --> ETL
QA[Quality System] --> ETL
ETL --> ERP
ETL --> WH
ETL --> TMS[Transport Portal]
ETL --> FIN[Finance]
ETL --> AI[AI / Analytics]This looks efficient on paper.
But the platform is now responsible for two very different jobs:
- Running operational business processes
- Feeding analytical and AI workloads
Those jobs have different priorities.
| Concern | Integration platform | ETL / AI platform |
| Main purpose | Operational system communication | Analytics and insight |
| Failure handling | Immediate support, retry, alerting | Reload, reprocess, reconcile |
| Time sensitivity | Business-process dependent | Often batch or near-real-time |
| Data shape | Contract-driven messages | Analytical models and history |
| Ownership | Integration / application operations | Data / analytics team |
| Correctness | Correct when used | Can often become correct later |
The better architecture
The integration platform should own operational flows.
The ETL and AI platform should consume from stable, governed sources.
%%{init: {'theme': 'dark'}}%%
graph TD
ERP[ERP] --> INT[Integration Platform]
WH[Warehouse] --> INT
PROD[Production] --> INT
QA[Quality System] --> INT
TMS[Transport Portal] --> INT
FIN[Finance] --> INT
INT --> ERP
INT --> WH
INT --> PROD
INT --> QA
INT --> TMS
INT --> FIN
INT --> EVENTS[Operational Events / Canonical Data]
EVENTS --> ETL[Cloud ETL Platform]
ETL --> LAKE[Data Lake / Warehouse]
LAKE --> AI[AI / Analytics]This separation gives each platform a clean responsibility.
- The integration platform keeps operations running
- The ETL platform prepares data for analysis
- The AI platform consumes governed and explainable data
The AI platform should not become the owner of operational truth.
It should consume from systems and integration events that are already understood, validated and traceable.
Why AI makes this more important
AI does not remove the need for integration architecture.
It increases it.
An AI model can only be useful if the data it consumes is meaningful.
- What does this stock number represent?
- When was it valid?
- Was it corrected later?
- Was this batch approved or only produced?
- Was the order cancelled, delayed or partially fulfilled?
- Which system owns the truth?
These are integration and data lineage questions before they are AI questions.
If the operational data flow is unclear, AI will automate the confusion.
AI should consume from controlled flows
In the seafood company, an AI model may predict demand, production capacity or waste.
But it needs data that has operational meaning:
- Confirmed orders, not abandoned drafts
- Approved quality data, not temporary production notes
- Actual stock, not stale warehouse extracts
- Real shipment status, not optimistic planning data
- Corrected historical data, not raw failure states
The integration platform helps define and expose these flows clearly.
The ETL platform can then store, model and prepare the data for reporting and AI.
The rule of separation
A practical rule:
If the flow is needed to run the business, it belongs in the integration platform.
If the flow is needed to understand the business, it belongs in the ETL and AI platform.
Some data will move between both worlds.
That is fine.
But the direction of responsibility should be clear:
%%{init: {'theme': 'dark'}}%%
graph LR
OPS[Operational Systems] --> INT[Integration Platform]
INT --> BUSINESS[Business Processes]
INT --> GOVERNED[Governed Operational Data]
GOVERNED --> ETL[ETL / Data Platform]
ETL --> AI[AI / Analytics]The integration platform should feed the analytical platform.
The analytical platform should not quietly become the operational backbone.
The real lesson
Cloud ETL platforms are useful.
AI platforms are useful.
But they do not replace integration architecture.
Before a company can safely use AI on operational data, it needs to know:
- Where the data comes from
- Which system owns it
- How it moves
- How failures are detected
- How corrections are handled
- What the data means in business terms
AI does not make integration less important.
It makes poor integration more expensive.
The integration platform keeps business data reliable in motion.
The ETL and AI platform turns reliable data into insight.
Both are needed.
They should not be the same thing.