Most systems don’t fail because of complex business logic.
They fail because of how they are connected.
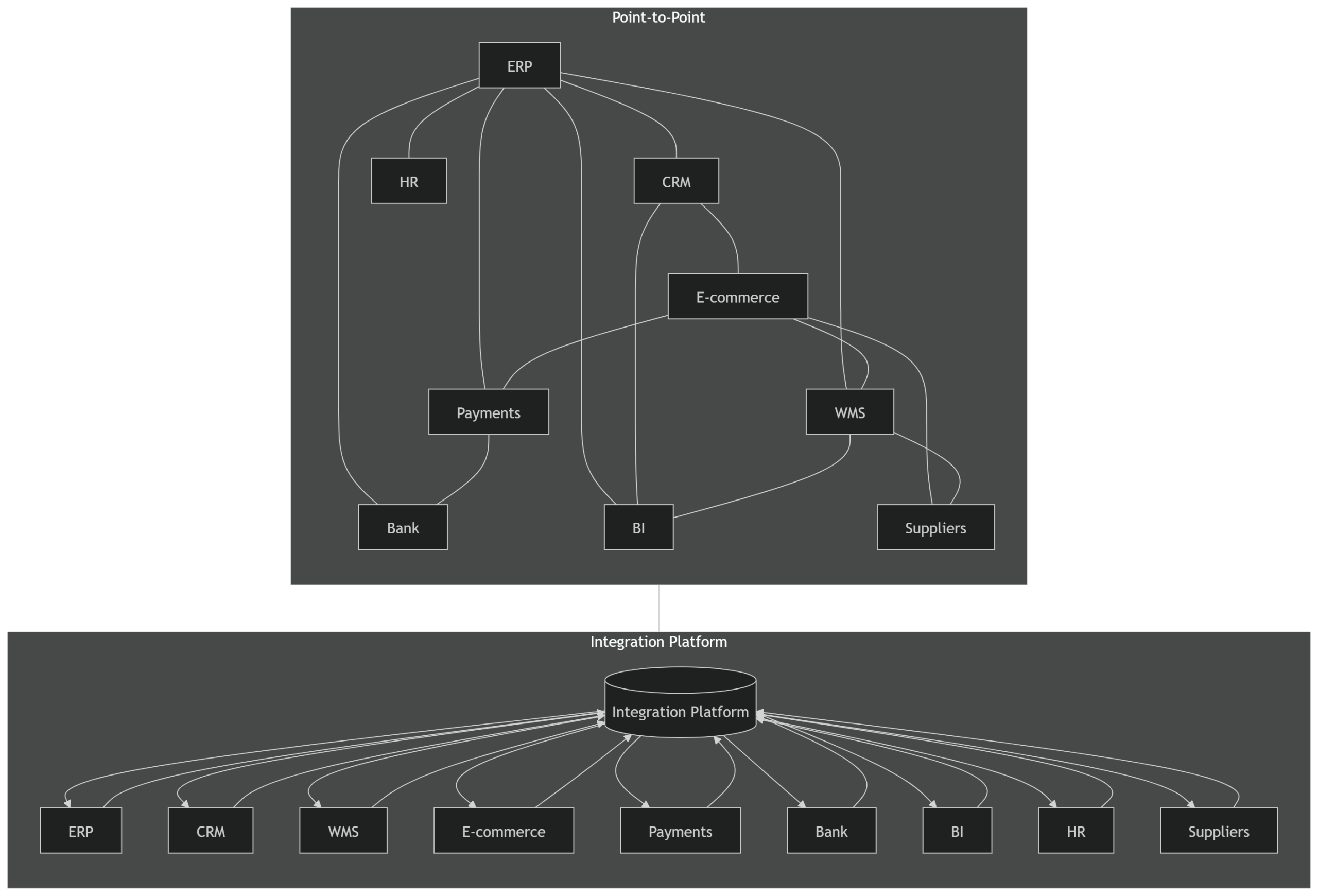
Point-to-point integrations are not usually chosen as an architecture.
They are what happens when integration architecture is not owned.
A system needs data, so it calls another system.
A report needs numbers, so a scheduled export is added.
A new department needs the same data, so another connection appears.
No one designs the whole.
Connections accumulate.
Over time, the system landscape stops being a set of systems.
It becomes a network of implicit dependencies.
A plausible business example
Imagine a mid-sized seafood processing company.
It has production facilities, cold storage, transport partners, sales teams, finance, quality control, and customers who expect accurate delivery information.
The company uses different systems for different jobs:
- ERP for orders, invoicing, items and customers
- Warehouse system for stock, lots and cold storage
- Production system for batches, yield and packing
- Transport portal for shipment booking and tracking
- Quality system for certificates, deviations and approvals
- Data platform for reporting, forecasting and AI analysis
At first, the integrations are simple.
The ERP sends orders to the warehouse.
The warehouse returns stock status.
The production system sends batch information.
Finance receives invoice data.
Each integration makes sense in isolation.
The problem appears when they become dependent on each other.
%%{init: {'theme': 'dark'}}%%
graph LR
ERP[ERP] --> WH[Warehouse]
WH --> ERP
ERP --> PROD[Production]
PROD --> QA[Quality System]
PROD --> WH
WH --> TMS[Transport Portal]
ERP --> FIN[Finance]
PROD --> DATA[Data Platform]
WH --> DATA
QA --> DATANow a delayed batch update can affect stock levels, transport booking, customer delivery promises, invoice timing, reports and AI forecasts.
The integration is no longer just moving data.
It is carrying business trust.
The hidden complexity
What starts as a few integrations quickly becomes a dependency graph.
Each connection introduces:
- Knowledge of another system’s contract
- Dependency on another system’s availability
- Responsibility for retries, errors and edge cases
- Unclear ownership when data is wrong
- Manual investigation when something fails
Individually, these are manageable.
Collectively, they create a system no one fully understands.
There is no single place where the full data flow is visible or owned.
This is the core problem:
logic is no longer inside systems — it is distributed between them.
The scaling law
Point-to-point integrations do not scale linearly.
The number of possible connections grows with the number of systems:
- 3 systems → 3 connections
- 6 systems → 15 connections
- 10 systems → 45 connections
- 20 systems → 190 connections
Every new system increases the number of relationships that must be understood, tested and maintained.
This is where most teams lose control.
Not because the individual systems are too complex, but because the connections are.
Failure is not binary
Integrations rarely fail in obvious ways.
Failures are often:
- Partial — only some data is transferred
- Delayed — data arrives too late to be useful
- Silent — an error is logged, but no one observes it
- Semantic — the data arrives, but means something different than expected
This creates a dangerous state:
Systems appear to work — until someone depends on the data.
The system does not crash.
It becomes unreliable in ways that are hard to detect.
The scheduled script problem
A common pattern is scheduled scripts moving data between systems.
They work because they are:
- Simple to implement
- Low cost
- Easy to understand in isolation
But they often lack:
- Central monitoring
- Alerting
- End-to-end traceability
- Retry handling
- Clear ownership
In the seafood company, a scheduled stock export fails on Friday night.
The warehouse system still works.
The ERP still works.
The reporting platform still works.
But the data is stale.
By Monday morning, sales sees stock that is no longer available. Transport planning is based on old volumes. Finance expects invoices for orders that should have been delayed. The AI forecast consumes incorrect inventory data and produces confident nonsense.
The result is not constant failure.
It is uncertain correctness.
Why point-to-point breaks
Point-to-point is not inherently wrong.
It works when:
- There are few systems
- Integrations are simple
- Change is infrequent
- Ownership is clear
It breaks when:
- The number of systems grows
- Systems evolve independently
- Business processes cross many applications
- No central ownership exists
- No one can see the whole flow
The problem is not connections.
It is unmanaged connections.
The real issue
At small scale, point-to-point is efficient.
At medium scale, it becomes fragile.
At large scale, it becomes unmanageable.
By the time teams realize this, the problem is no longer fixing one integration.
It is regaining control over a system where:
- No one owns the full data flow
- No one sees the full picture
- No one can change it safely
- No one trusts the data completely
Point-to-point does not fail suddenly.
It decays until change becomes dangerous.
In the next post, we introduce the control layer that prevents this: the integration platform.
Leave a Reply